Ludwig is a deep learning toolbox that allows users to train and test deep learning models on a variety of applications, including many natural language processing ones like sentiment analysis.
Ludwig is a declarative machine learning framework that makes it easy to define machine learning pipelines using a simple and flexible data-driven configuration system. Ludwig is suitable for a wide variety of AI tasks, and is hosted by the Linux Foundation AI & Data.
The configuration declares the input and output features, with their respective data types. Users can also specify additional parameters to preprocess, encode, and decode features, load from pre-trained models, compose the internal model architecture, set training parameters, or run hyperparameter optimization.
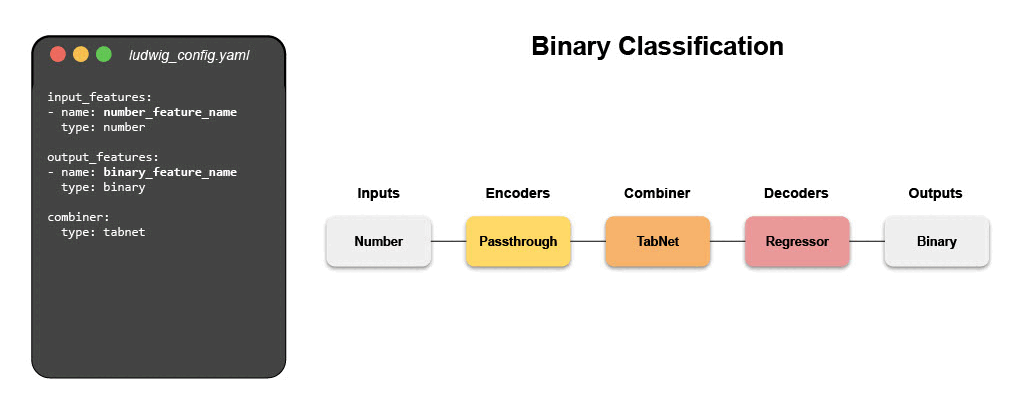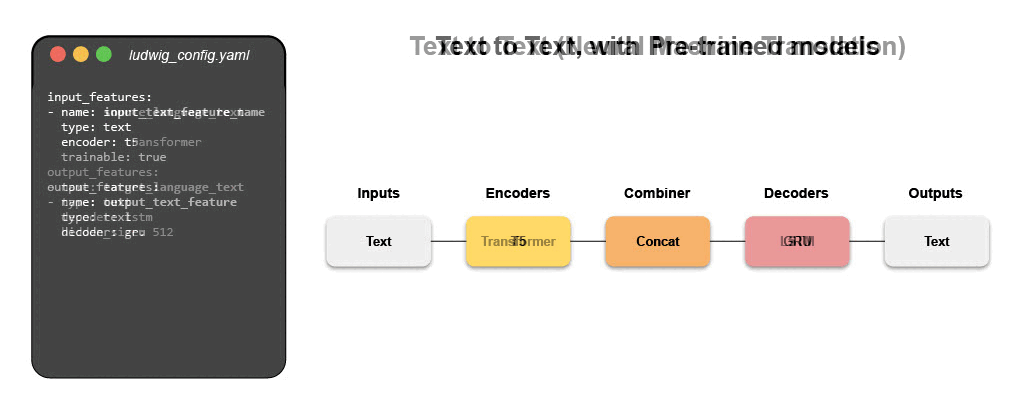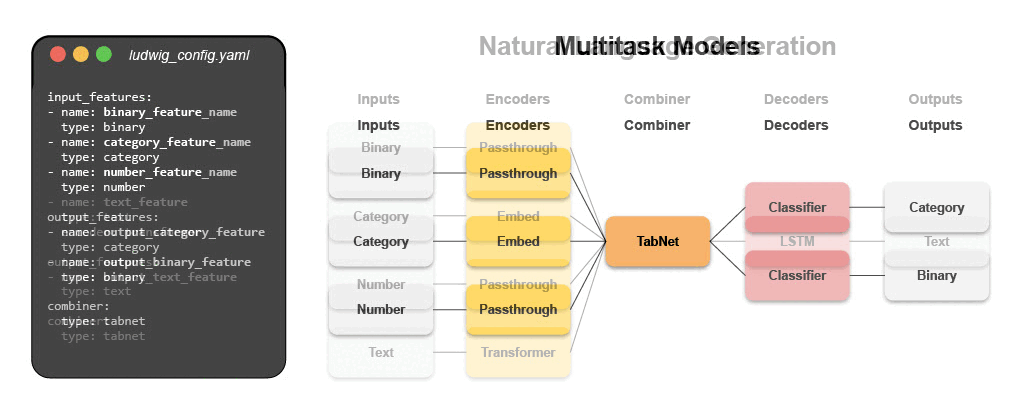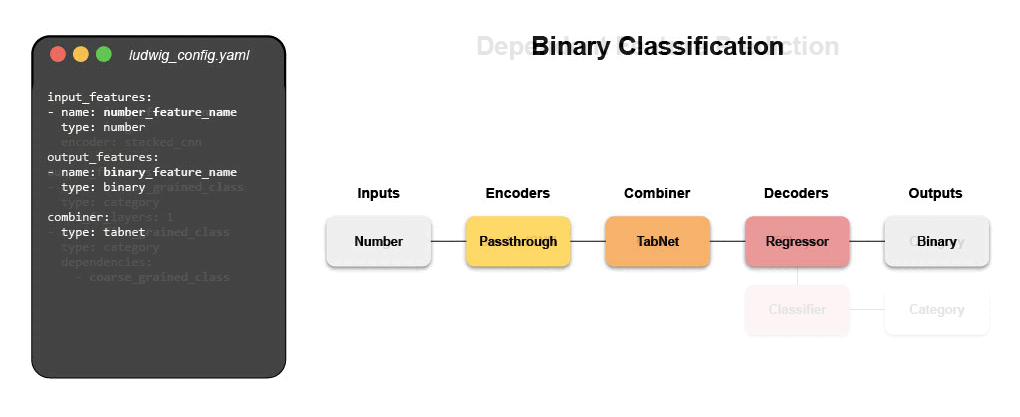
Ludwig will build an end-to-end machine learning pipeline automatically, using whatever is explicitly specified in the configuration, while falling back to smart defaults for any parameters that are not.
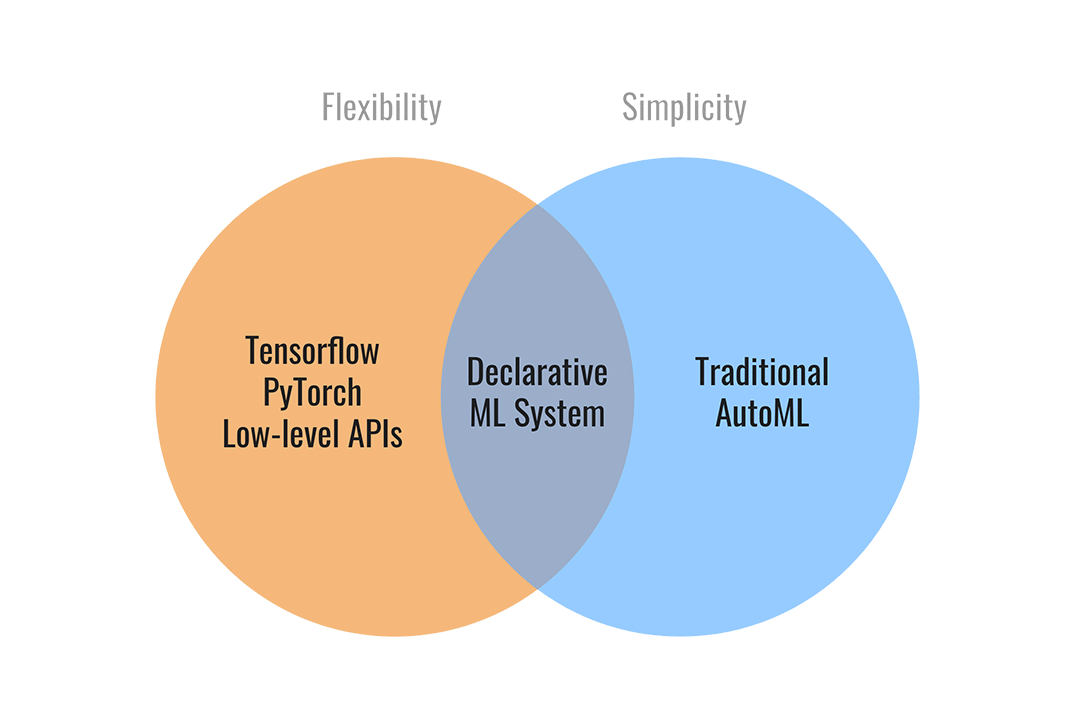
Declarative Machine Learning¶
Ludwig’s declarative approach to machine learning empowers you to have full control of the components of the machine learning pipeline that you care about, while leaving it up to Ludwig to make reasonable decisions for the rest.
Analysts, scientists, engineers, and researchers use Ludwig to explore state-of-the-art model architectures, run hyperparameter search, scale up to larger than available memory datasets and multi-node clusters, and finally serve the best model in production.
Finally, the use of abstract interfaces throughout the codebase makes it easy for users to extend Ludwig by adding new models, metrics, losses, and preprocessing functions that can be registered to make them immediately useable in the same unified configuration system.